Write-up by Ilya Kuzovkin of our publication in Nature Communications Biology that is a result of a long research carried out by myself, Jaan Aru and Raul Vicente from Computational Neuroscience Lab and our collaborators from Neuroscience Research Center in Lyon, France.
Human visual cortex, the system we use to perceive the world around us, consists of several areas, where each subsequent area is responsible for recognizing more and more complex visual structures. Area V1 of primary visual cortex on the very back of the brain starts the process by detecting simple visual features, such as straight lines, edges, transitions between colors, etc.
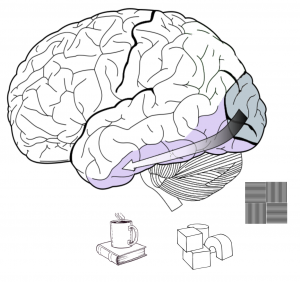
Certain neurons are responsive to certain visual features and if such features appear in your visual field those neurons detect them and send a signal further along the ventral stream, where the detection of more complex objects, like geometrical shapes, happens. Once those objects are identified as well, the signal is sent even further, and so it goes, deeper and deeper into the hierarchy of visual areas to create visual understanding of what our eyes see.
Keeping this hierarchical structure of human visual cortex in mind, let us have a look into inner workings of deep convolutional neural networks. The concept of artificial neural network is loosely based on biology of our brain.
Artificial network consists of artificial neurons that accumulate the inputs from the neurons below them and send accumulated output to the neurons above, the connections between those neurons are called weights. By changing the weights we can train the network to react in a certain ways to certain inputs. Deep convolutional neural networks are current state of the art in computer vision and are responsible for achievements like this one:
Artificial neural networks organize neurons in layers that follow each other (sounds familiar, doesn’t it?). Here is an example of an architecture called AlexNet that has 8 layers:

The first is the input layer, where one neuron corresponds to one pixel of an image. After the input layer the network has five convolutional layers. A convolutional layer is a collection of filters that are applied to an image.
Each filter is a 2D arrangement of weights that represents a particular visual pattern. A filter is convolved with the input from the previous layer to produce the activations that form the next layer. Each layer consists of multiple filters. A filter is applied to every possible position on an input image and if the underlying patch of an image coincides with the pattern that the filter represents, the filter becomes activated and translates this activation to the artificial neuron in the next layer (remember how the biological neurons were responsible for detecting certain visual features?).
That way, nodes of the first convolutional layer tell us where on the input image each particular visual pattern occurred. Nodes of the second layer tell us which visual features that were detected by the first layer are important for visual understanding of the object on the image, and so on.
An interesting observation was made when researchers decided to see what exactly are those patterns and features that each layer of the network tries to detect. It turned out that the deeper you go into the layers of DCNN the more complex are the visual patterns represented by the neurons of that layer:

Convolutional layers are followed by 3 fully connected layers. Each node in a fully connected layer is, as the name suggests, connected to every node of the previous layer allowing the network to decide which of those connections are to be preserved and, which are to be ignored. Have a look at http://scs.ryerson.ca/~aharley/vis/conv to interactively play with a small model of a convolutional neural network and see how it works.
By now I have alluded multiple times to the similarities between the biological and artificial visual systems. The question “how similar are they?” is begging to be asked. It was exactly the question we tackled in our research. The hierarchical structure of both systems is a well-known fact, the attempt to compare them was also not a novel idea. What was special about our take on this problem was the unique dataset that allowed us to look deeper and characterize what type of brain activity carries those similarities with the hierarchical architecture of an artificial neural network.
The data we got from Lyon Neuroscience Research Center were collected from the electrodes implanted directly inside subjects` brains:
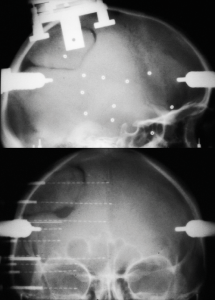
While wearing the electrodes test subjects were shown a set of images of different categories (animals, natural scenes, houses, etc) and the activity of their brain was recorded.
We took the same images and showed them to AlexNet that was trained to classify images into 1000 categories (cats, dogs, houses, cars, etc). Now we have activations of both biological and artificial systems “looking” at the same set of images! Let’s compare!
We have split human visual system into 5 regions and applied a technique called Representational Similarity Analysis to see activity of which of the layers of deep convolutional neural network is closest to each of the 5 brain regions. This allowed us to obtain mappings between brain regions and layers of the network that looks like this:
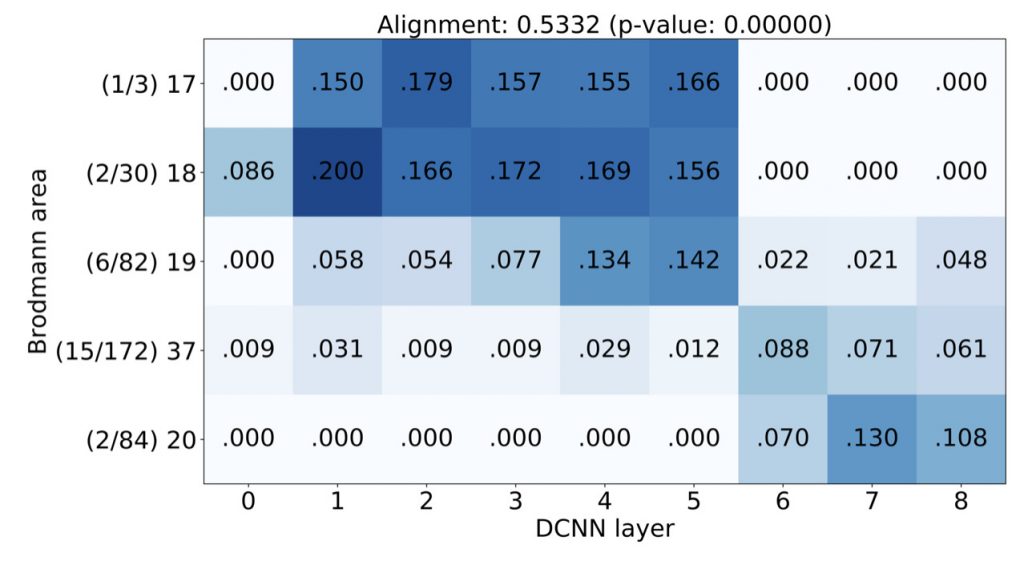
The diagonal trend you can see on this image was what we were after, it indicates that lower layers of DCNN map better to early areas of human visual cortex, while higher layers map to higher brain areas. This was an encouraging, but not novel, result, that confirmed the observations made by other researchers using other neuroimaging techniques (fMRI and MEG).
Those other techniques have, however, certain limitations: fMRI cannot pinpoint when in time the activity happened and cannot track the change of that activity in time; MEG can detect only the activity that is strong enough to create a magnetic field detectable outside human skull, thus with MEG one can see only aggregated activity. Implanted electrical electrodes, on the other hand, provided us with a trace of the activity with a millisecond precision and we also know their anatomical implantation sites.
When one measures electrical responses from the brain one can see a complex pattern of activity. Those activity patterns are grouped together based on their frequency: alpha (8 to 14 times per second), beta (15 to 30 Hz), gamma (from 30 to ~70 Hz), high gamma (more that 70 Hz) and some other.
Neuroscientists have observed that certain bands are more prominent during certain types of activity, for example alpha becomes stronger when a human is relaxed, beta and gamma come up during active engagement in a task, and so on. Figuring out which type of activity coincides the most with the hierarchy of layers of an artificial system would reveal an important insight into the functional role of that activity.
Our main result, reflected also in the title of the article “Activations of deep convolutional neural networks are aligned with gamma band activity of human visual cortex” is that low gamma (30 to 70 Hz) and high gamma (70 to 150 Hz) are best aligned with the activity of DCNNs, indicating that what happens in human brain at those frequencies is most similar to what DCNNs are doing.
This finding fits with neuroscience research that has independently suggested that gamma activity is important for object recognition. Thanks to our work we can better understand which computations are reflected by these signals at the gamma frequency during visual processing.
The ultimate quest of neuroscience is to understand how brain codes, stores and transmits information and how all those firings of billions of tiny neurons lead to complex mental process and behaviours we, human, are capable of. This work provides yet another piece of this huge puzzle and indicates the important role that artificial intelligence algorithms can play in understanding human brain.


