Joosep Hook, Kea Kohv, Lisanne Siniväli, Li Merila, andmeteaduse magistriõppe 1. kursus.
Masinõpe on üks Tartu Ülikooli arvutiteaduse instituudi populaarsemaid magistriõppe aineid, mis lõpeb masinõppe abil tõsielulise probleemi lahendamisega. Võimalike projektide seas on nii ettevõtete ja riigi pakutud kui ka ise välja valitud probleeme. Neljane tiim andmeteaduse magistri esmakursuslasi jagab oma õppetunde Tartu pildipanga piltide märgendamisest.
Meie tiim osales Tartu pildipanga piltide märgendamise Kaggle võistlusel. Meie projekti suurem eesmärk oli treenitud mudeli abil märgendada 134 000 praegu märgendamata Tartu pildipanga pilti. Pildid on hetkel jaotatud üldiste teemade järgi kaustadesse. Märgendatud pilte on aga lihtsam otsida ning kasutada erinevates artiklites, blogipostitustes ja turundusmaterjalides.
Andmestik oli ülesande raskust arvesse võttes tilluke: 201 treeningpilti ja 86 testpilti, millest mitmed olid puudu. Erinevaid võimalikke märgendeid oli kokku 92. Märgendeid võis igal pildil olla mitu ning keskeltläbi oli igal pildil 4 märgendit. Mõni märgend tähistas üldise objekti (lilled, inimesed) asemel hoopis midagi kindlat: näiteks “emajõe-peipsi barge jõmmu”, mis tähistab Emajõe-Peipsi tüüpi lodi nimega Jõmmu. Seda lotja võivad Tartu elanikud näha soojadel suvepäevadel Emajõel sõitmas.
1. Väljaspool klassiruumi ei ole andmestik suur, puhas ja klassid tasakaalus. Vähemasti mitte korraga.
Kui ootad, et päriselulist probleemi lahendades on andmestik korrektselt ja loogiliselt märgendatud, treeningandmeid küllaga ning 134 000-st seni veel märgendamata pildist on treeningandmeteks esinduslik valim, siis tõenäoliselt pettud.
Kõige sagedamini esinesid piltidel märgendid “inimesed” ja “puud” (“people”, “trees”), mõlemat ligikaudu 80 pildil, kuid paljud märgendid esinesid vaid 2-5 pildil. Lisaks oli kentsakaid testpilte, mille sarnaseid treeningandmestikus üldse ei olnud. Seljakotis istuva kassi pilti vaadates kehitas masinõppemudel õlgu ning pakkus, et pildil võiksid olla puud (“trees”). Lisaks tuvastas masinõppemudel inimesena (“human”) vaid Tartu linnapead, sest treeningandmestikus oli see märgend Urmas Klaasi piltidel.
2. Kontrolli algandmeid ja paranda vead
Inimesed teevad ikka näpuvigu ning ka selles andmestikus esines valesti või kummaliselt märgendatud treeningpilte. Märgendamise stiil ei olnud ühtlane. Seetõttu pidime tegema käsitööd ja treeningpiltide märgendeid parandama.

Samas kõike parandada ei saa. On võimalik, et treeningandmestik ei ole esinduslik valim suuremast üldkogumist. Meie projekti treeningandmete põhjal õppis mudel tuvastama vaid punaseid busse (“red bus”), kuna see oli ainus busside kohta käiv märgend. Teist värvi bussid jääksid piltidel tuvastamata. On ebausutav, et nende 134 000 pildipanga pildi seas esinevad vaid punased bussid. Samas on võimalik, et pilte otsivaid inimesi huvitavad just nimelt Tartu punased bussid. Vaid andmestiku looja saab otsustada, kas selline märgendus oli tahtlik või tahtmatu.
3. Mudel märgendi kohta lihtsustab ristvalideerimist
Kuna meie projektis oli palju üksikutel piltidel esinevaid märgendeid, pidime nuputama, kuidas viia läbi ristvalideerimist [1] nii, et andmestiku tükeldamisel oleksid igas tükis kõik märgendid esindatud. Leidsime kaks lahendust: set cover algoritmi kasutamine ja iga märgendi kohta mudeli loomine.
Mitmese märgendamise puhul on juba 1-kordne ristvalideerimine keeruline, k-kordsest rääkimata. Tähistagu treeningpildile x omistatud märgendite hulka m(x). 1-kordseks ristvalideerimiseks tahame jaotada treeningpildid X mittelõikuvatesse osahulkadesse Xtreen ja Xval nii, et
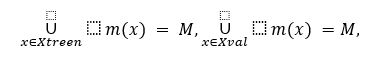
kus M tähistab kõigi võimalike märgendite hulka. Teisisõnu, tahame jaotada treeningpildid kahte eraldi osasse nii, et kõik võimalikud märgendid on mõlemas osas esindatud. Üks lahendus on vaadelda seda kui set cover probleemi, mille eesmärk on leida väikseim osahulkade (treeningpiltide märgendite) kombinatsioon, mille ühend annab kokku universaalhulga (kõikvõimalike märgendite hulk M). Lihtsaim algoritm selle ülesande lahendamiseks aitab meil jagada treeningandmed kahte ossa, kuid ei aita meil andmeid jagada rohkematesse osadesse.
Alternatiiv on vaadelda mitmelise märgendamise ülesannet hoopis mitme eraldiseisva märgendamise ülesandena, kus treenitakse |M| erinevat mudelit, üks iga märgendi kohta. Treenitud mudel ütleb, kas pildil on vastav märgend või mitte. Mudeli treenimine märgendi kohta on küll paindlikum, sest muudab mitmekordse ristvalideerimise lihtsaks, kuid võib nõuda rohkem arvutusvõimsust võrreldes ühe mudeli treenimisega.
4. Väheste treeningpiltide puhul tasub proovida few-shot learning mudeleid
Kui treeningandmestik on väga väike, ei pruugi erinevad andmete rikastamise meetodid olla piisavad, et treenida tuhandete või miljonite parameetritega masinnägemise närvivõrke. Lisaks on tuntuimad eeltreenitud masinägemise närvivõrgud nagu ResNet suutelised klassifitseerima ainult neid klasse, milleks nad on eeltreenitud (näiteks 1000 ImageNet klassi) ning vajavad lisatreenimist, et klassifitseerida muid klasse. See vajab jällegi piisavalt treeningandmeid. Üks lahendus probleemile on nn few-shot learning mudelid.
Vastandudes many-shot learning mudelitele, mis vajavad uue probleemi lahendamiseks palju andmeid, on few-shot learning mudeleid võimalik kasutada väheste treeningandmetega ja zero-shot learning mudeleid täiesti ilma treeningandmeteta.
Näiteks CLIP (Contrastive Language-Image Pre-Training) on zero-shot võimekusega mudel, mis on eeltreenitud piltide ja teksti paaridel [3]. Andes CLIP mudelile ette pildi ja vektori eri sõnade või tekstijuppidega, saab CLIP-i abil leida iga tekstijupi sarnasuse selle pildiga.

Näiteks kui CLIP mudelile anda ette ülalolev suudlevate tudengite pilt ja viie-elemendiline tekstivektor, annab CLIP koos softmax aktivatsiooniga sellised tõenäosused:
0.002 a statue
0.997 a statue of a kissing couple under an umbrella
0.001 a fountain
0.000 a building
0.000 a garbage bin
Kuna Tartu pildipanga projektis võis olla igal pildil mitu märgendit ning meil oli ka treeningandmeid, mida kasutada, oli mõistlikum eraldada eeltreenitud mudelitest piltide arvulised tunnused (image feature extraction) ning nende arvuliste tunnuste abil treenida ennustusmudel.
5. Järjekindlus, katsetamine ja ideede vahetus viib sihile!
Mida rohkem katsetada, seda enam võib leida hästi töötavaid masinõppemudeleid. Meie tiim katsetas palju erinevaid mudeleid piltidest arvuliste tunnuste eraldamiseks, nende seas ResNet50, CLIP, openCLIP, Histogram of Gradients, Hue Vector, BEiT, DeiT III, ALBEF. Katsetasime ka mitmeid erinevaid ennustusmudeleid, nii puudel põhinevaid (nt otsustusmetsi), tehisnärvivõrke, lineaarseid mudeleid kui ka k-lähima naabri meetodit ja naiivset Bayes’i.
Avastasime, et kui andmeid on vähe, võivad lihtsad ennustusmudelid hästi töötada. Kõige paremini töötas tunnuste eraldamiseks openCLIP ja ennustusmudelina logistiline regressioon. Lisaks proovisime erinevaid andmete rikastamise meetodeid, tunnuste standardiseerimist ja treeningandmestiku täiendamist vabalitsentsi piltidega.
Projektiga varakult alustamine, iganädalased arutelud ja Kaggle-is tihti esitamine viisid sihile. Meie tiim võitis selle Kaggle võistluse. Samas olid võidust veel väärtuslikumad saadud õppetunnid ja innustus osaleda masinõppe võistlustel ka tulevikus.
Tiimi lõppesitluse (inglise keeles) võib leida siit.
[1] Ristvalideerimine on levinud meetod masinõppealgoritmi hüperparameetrite valimiseks. Treeningandmed jaotatakse mitmeks võrdse suurusega osaks, millest iga osa kasutame ühel korral mudeli valideerimiseks, teisi osi treenimiseks. Treeningandmete kolme ossa jaotamisel saame treenida ning valideerida hüperparameetrite komplekti kolme erineva andmestiku peal. Kui me kasutame 1-kordset ristvalideerimist, siis meie valitud hüperparameetrid sõltuvad rohkem sellest, millised andmed juhuslikkuse tõttu treening- ja valideerimisandmeteks valiti.
[2] Scikit-learn MultiOutputClassifier võimaldab lisatööta treenida ühe mudeli märgendi kohta. Sarnast võimalust pakub ClassifierChain erinevusega, et n-s mudel saab lisasisendiks n-1 eelneva treenitud mudeli väljundid.
[3] https://github.com/openai/CLIP

