Data privacy has become trending, and nowadays, people are talking more and more about it. With process mining, privacy becomes more relevant. Because process mining makes it easier to expose the actual business reality. With automatic process discovery, we can reverse engineer the activities that have been performed within the organization and the hand-offs between resources that execute such activities. Hence, it is easier and faster to expose confidential information with process mining techniques. This information can be used in deriving different knowledge about an individual’s personal information.

Due to data privacy concerns, governments came up with legislation to protect the privacy rights of their people, such as the General Data Protection Regulation (GDPR) within the EU. Hence, privacy is becoming a legal responsibility rather than a social one. Therefore, it is clear that privacy preservation aspects will become a mandatory step within the Business Process Management life cycle. Specifically, it is necessary to incorporate privacy aspects in the discovery, analysis, and monitoring phases.
The main objective of this blog post is to introduce some concepts related to Privacy-Preserving Process Mining (PPPM). Once you are done reading, you will understand that there is much more to what you already knew as ‘privacy.’
Let’s start with the general definition of privacy-preserving data mining.
“It is the process of extracting knowledge from data while preserving privacy.”
This definition mentions two parts of it:
- Preserving data privacy (personal information and other organizational sensitive information).
- Preserving the utility of the data (the output of the privacy techniques is still useful and can generate meaningful insights).
The definition tells us that it is not an easy goal. We need techniques that can preserve the privacy of individuals, but at the same time, those techniques cannot entirely distort the data and corrupt its analytical value. The successful combination of privacy preservation and process mining is known as ‘Privacy-Preserving Process Mining’ [1]. Below, I introduce underlying concepts related to privacy.
Privacy Related Attributes
Have you ever considered what type of data would disclose an individual’s privacy? The first thing that comes to mind is case identifiers, customer’s name, and email address. But is it only those? No, there is much more to it. Therefore, let’s look into a formal classification of privacy-related attributes.
- Case ID: directly used to identify a case.
- Case attributes, e.g., name, email, Social Security Number (SSN).
- Case variant: which is the sequence of activities that have been executed for the case.
- Quasi-Identifiers: attributes can be combined to identify an individual (age, gender, profession, race, zip code).
- Sensitive Attributes: attributes that individuals do not want to reveal (diagnosis, sexuality, salary, credits, payment transactions, financial situation).
I am pretty sure that you are certain of the Case IDs and Case attributes, as they can single out an individual. Also, you may think that if we hash these attributes, that would be enough to hide the identity. But can you think a little more about the quasi-identifiers? Think about an individual for whom we don’t know their Case ID, name, email, or SSN, but we know some details like gender, age, profession, race, and zip code. By any chance, if that person is the only female software developer of age 36 from her village, then we can easily link the case to that person, even if we don’t know any case IDs. Dangerous, right?
Furthermore, suppose we eliminated all extra attributes and released only Case ID, Timestamp, and the activity label. In that case, an attacker can use the trace variant to link a case to an individual. Think of someone who knows that the individual of interest has been through the reception desk at that specific time or that the individual of interest is the only patient with breast cancer in this hospital. It is pretty easy to link the case to that individual. Therefore, PPPM is not only about simply hashing the Case IDs and anonymizing case attributes, but there’s more to it. Sensitive attributes are the pieces of information that individuals don’t want to reveal about themselves. Some examples are diagnosis, sexuality, salary, credits, payment transactions, and financial situation.
The following example illustrates the privacy attribute classification.
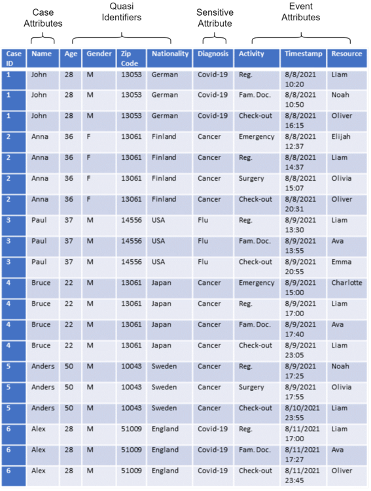
Currently, organizations depend on applying pseudonymization techniques to protect their event logs. Below, we describe some of the pseudonymization techniques:
- Suppression: replaces some attribute values with a symbol like ‘$’ to indicate that this part of the value is held. For example, the zip code ‘51009’ is replaced with ‘510$$’.
- Generalization: replaces the attribute’s values with a generalized value of its class. For example, instead of the age is 36, that can be replaced by 30-40.
- Swapping: swaps some attribute values with each other.
- Masking: transforms the name of the individual into its hash value.
Below is the result of applying some of the above techniques to the event log.
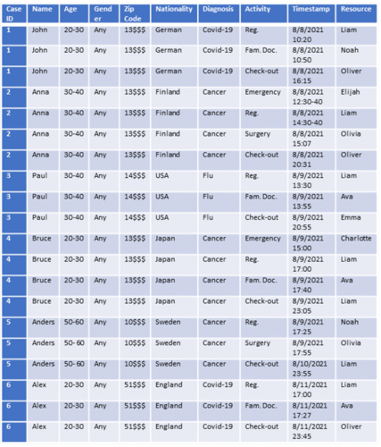
Up to now, we have talked about pseudonymization or de-identification of the privacy-related attributes. But then comes another question. Is it enough to apply the above pseudonymization techniques on the event log? Pseudonymization techniques don’t provide any privacy guarantees. So how do we know for sure that privacy is preserved? Can we even give a metric to report the level of privacy? To solve this problem, several ‘privacy models’ are defined. The beauty of privacy models is that they provide a formalized notion to measure privacy. Even some privacy models, like differential privacy provide mathematically proven guarantees. Following are some of the popular privacy models from the literature.
K-anonymity
K-anonymity is a group-based model that groups the cases in the event log such that each case cannot be differentiated from at least k-1 other issues. That grouping could include the quasi-identifiers. K-anonymity has been introduced to event logs in recent research.
Differential Privacy
Differential privacy is a model that injects noise into the data in the event log to promise the data owners that: “you will not be affected, adversely or otherwise, by allowing your data to be used in any study or analysis, no matter what other studies, datasets, or information sources are available”. Differential privacy obscures the data contributions from the individuals by injecting noise. This noise is drawn from a random distribution, quantified by a parameter called ε, which reflects the privacy budget. This is performed while ensuring that the anonymized event log still gives insights into the overall population and applying process mining to the output still gives useful results. Differential Privacy has been introduced to release event logs in recent research.
Secure Multi-Party Computation
This method allows different parties to jointly compute a common function while keeping the inputs private. It allows performing process mining under cross-organizational settings, where two or more organizations are willing to jointly perform process mining on their private event logs without sharing their logs.
Proposal
In this thesis, we propose a set of privacy-preserving approaches that we call Privacy-Preserving Process Mining (PPPM) approaches to strike a balance between the benefits an analyst can get from analyzing these event logs and the requirements imposed on them by privacy regulations (e.g., GDPR). We use differential privacy to achieve that goal. Also, in this thesis, we use secure multi-party computation protocols to enable organizations to jointly perform process mining over their data without sharing their private information.
The techniques proposed in this thesis have been proposed as open-source tools. The first tool is Amun, enabling an event log publisher to anonymize their event log before sharing it with an analyst. The tool is available on the cloud at http://amun.cloud.ut.ee/. Also, Amun is available as a docker image at https://github.com/Elkoumy/amun/tree/amun-flask-app. The second tool is called Libra, which provides an enhanced utility-privacy tradeoff. The source code of Libra is available at https://github.com/Elkoumy/Libra. The third tool is Shareprom, which enables organizations to construct process maps jointly. The source code of Shareprom is available at https://github.com/Elkoumy/shareprom.

