We are living in a world in which data is not just getting bigger; it is also getting more and more interconnected. Large graph analytics is a useful tool for gaining insights from large volumes of interconnected data and has applications in various fields such as social media, biology, and telecommunications. An example of the importance of large graph analytics is using knowledge graphs to integrate various datasets related to COVID-19 to understand the pandemic better and potentially find treatments.
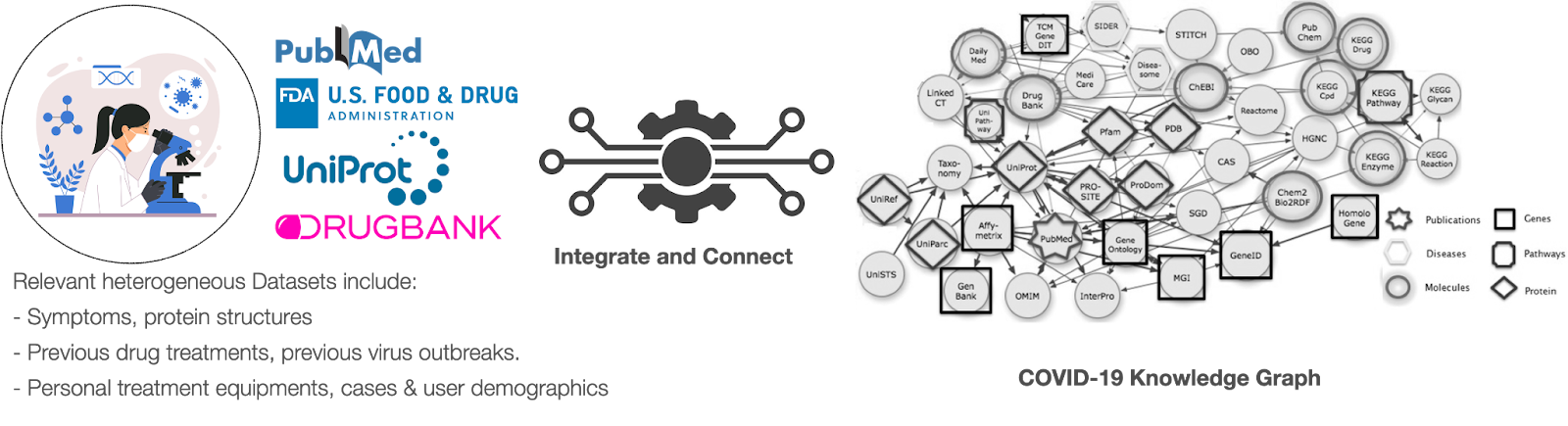
The graphs are getting too big!
Due to the large amounts of data that need to be processed for various applications, there is a need for scalable systems to handle large graph datasets efficiently. Examples of such datasets include Google KG, which contains over 18 billion facts, and Bio2RDF, which has 11 billion facts. As a result, there has been a lot of research and development in the field of graph processing, resulting in an increase in the number of systems designed for storing, managing, and processing graphs.
Graph Community Falls Back to Relational BD System!
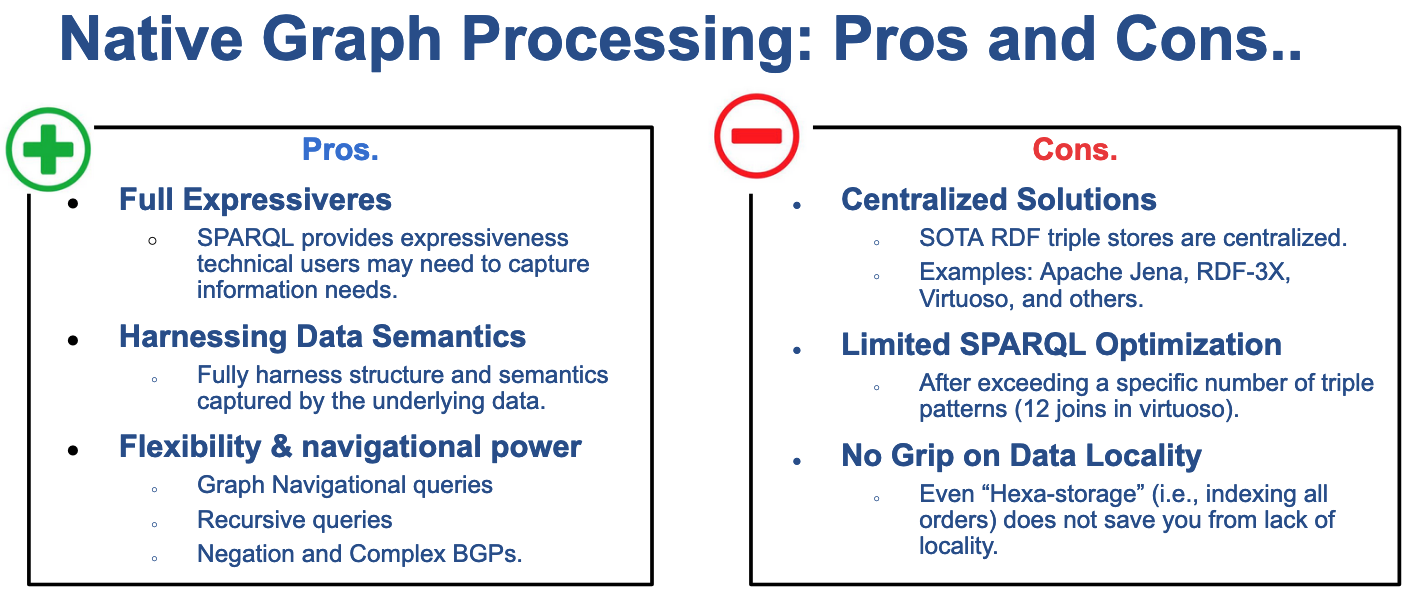
Native graph systems, such as Apache Jena and RDF-3X, can process and query RDF datasets using the SPARQL language and allow for complex queries and graph navigation. However, their centralized nature limits their ability to handle large-scale RDF datasets. As a result, the current solution for analyzing large graphs is to use existing big data systems, which have mature, distributed relational interfaces. This approach requires additional design decisions and can result in a loss of expressiveness and potential performance issues. Developing a native, scalable engine for querying graphs is still an open problem.
Using Big Data systems with a relational model for representing and processing graphs requires additional design decisions that cannot be made automatically. These decisions, such as the choice of schema, partitioning technique, and storage format, must be carefully considered. When processing large graphs in the relational model, the full expressiveness of graph query languages may be lost, and representing graphs in the relational schema can be challenging. Incorrect design decisions may be difficult to change in the future, especially for large volumes of data, and can significantly impact system performance. Making changes to the design can also be costly and require significant data engineering efforts.

The performance of Big Data systems with a relational model when processing graphs can vary depending on design decisions, such as schema, partitioning technique, and storage format. These trade-offs can make it difficult to determine the best option, and there is rarely a clear winner among the available choices. Additionally, the performance of a particular system may be highly dependent on the specific query workload, partitioning technique, and storage format being used. Changing any of these factors can significantly impact performance. As a result, it can be difficult to fairly evaluate or benchmark the performance of these systems when querying large graphs.

Research on performance analysis for querying large graphs often lacks a clear interpretation of the results. Previous studies have primarily focused on describing or diagnosing the performance of different experimental configurations rather than providing actionable insights. This approach can provide a limited understanding of the performance of big data systems when querying large graphs and can make it difficult to replicate the results.
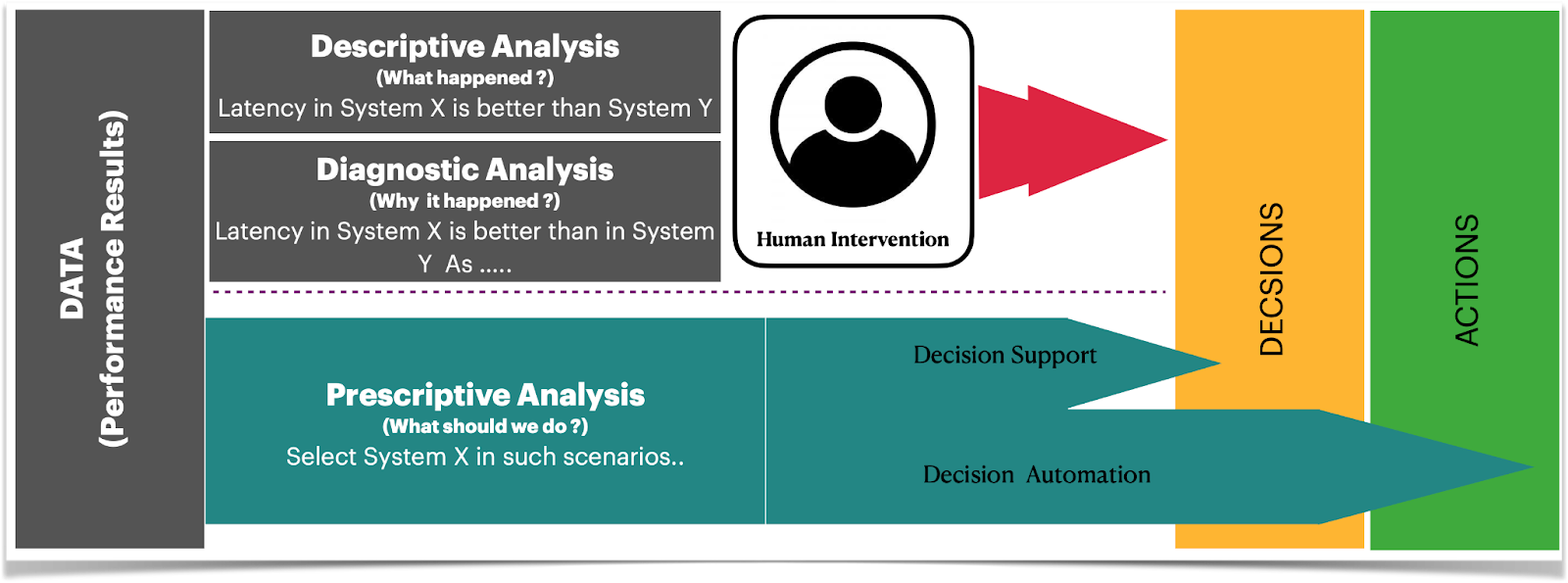
In this Ph.D. research, it is proposed that prescriptive performance analysis (PPA) can offer solutions to the limitations of previous approaches by providing actionable insights and guidance for improving performance. PPA reduces the need for human intervention by offering recommendations for steps to optimize the performance of big data systems when querying large graphs and can help navigate complex experimental solution spaces and consider trade-offs among different experimental dimensions, such as schema, partitioning, and storage. The research also focuses on enabling prescriptive analytics for big data systems when querying large knowledge graphs using ranking functions and multi-dimensional optimization techniques (called the “Bench-Ranking” framework). The Bench-Ranking criteria presented in this work are a simple yet effective method for supporting practitioners in their evaluation tasks, even when there are trade-offs among experimental dimensions. They aim to provide actionable insights into the problem of querying large knowledge graphs without requiring significant human intervention while abstracting away from the complexity of previous, limited approaches to performance analysis for big data systems.
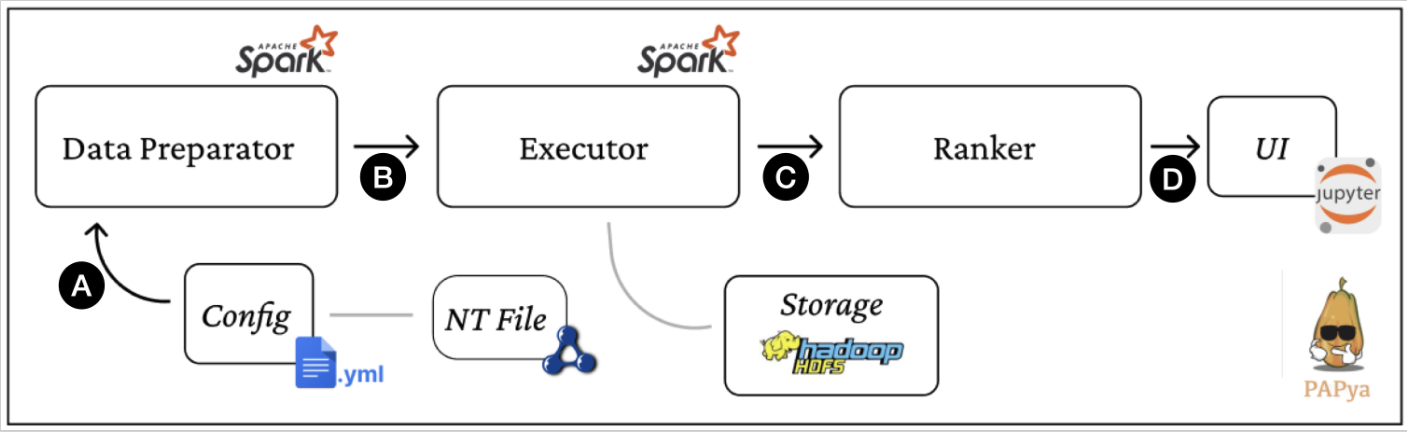
Lastly, we aim to provide the hook rather than the fish. Thus, we designed a tool called PAPyA, that practitioners can use to apply prescriptive analysis to their own use cases and scenarios, rather than focusing on a specific knowledge graph or RDF dataset. PAPyA is an open-source Python library that includes Bench-Ranking ranking techniques and evaluation metrics. It can prepare the solution space of various experimental dimensions, run experiments with a big data system, automatically collect performance results, and provide prescriptive analysis on the best-performing configurations. PAPyA is flexible and can be extended to include new experimental dimensions or options. It can also be used to extend ranking techniques and evaluation metrics.